
space.vars.SITENAME }}\*\* requires one special field to be defined on the entity that is being synchronized. These must be set up so that \*\* {{ space.vars.SITENAME }}\*\* can track the integration status of each item.
| Version | Type of field | Field Name |
| ------------------------------- | ----------------------------- | -------------------------------------------------------- |
| **For Version < 5.0** | Read only text | OH \_Last \_Update |
| **For Version >= 5.0 and <6.2** | Text Field (< 255 characters) | OH \_Created \_By |
| **For Version >= 6.2** | | No such fields needs to be added as part of prerequisite |
Refer [Custom field for Jira version < 6.2 section](#custom-field-for-jira-version-less-than-6.2) in appendix for details on how to create custom fields.
**Synchronize changes in Issue Type**
* When Jira is the target system in \*\* {{ space.vars.SITENAME }}**, to modify the issue type of the entity, the "Issue Type" field must be present on the edit screen of the configured entity types in \*\* {{** space.vars.SITENAME **}}**.
## System Configuration
Before you start with the integration configuration, you must first configure Jira. Click [System Configuration](https://docs.opshub.com/v7.215/integrate/configure-integrations/system-configuration) to learn the step-by-step process to configure a system.
Refer the screenshot given below for reference:
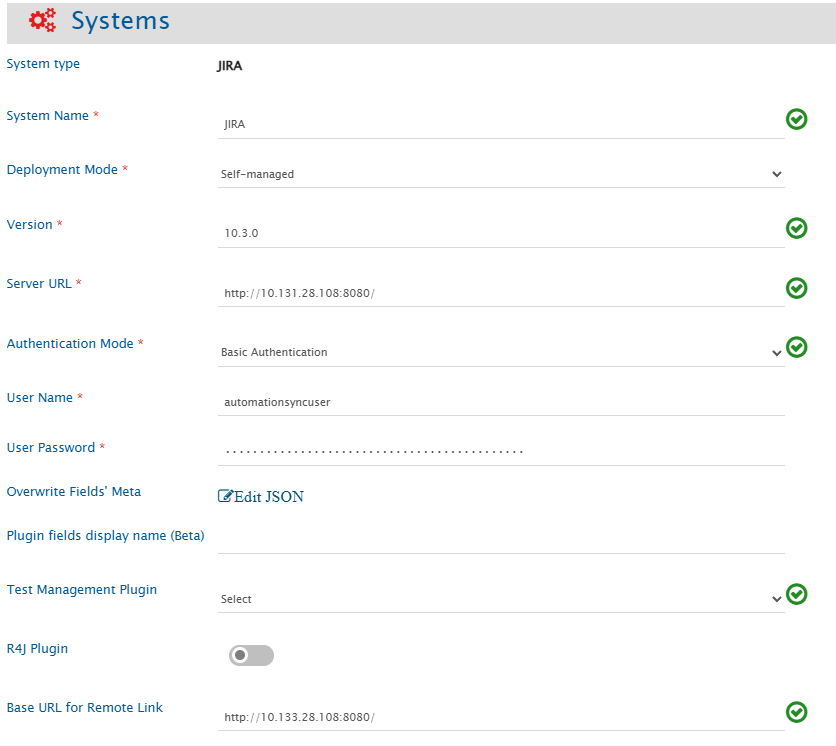
Choose a Jira plugin to sync test entities. space.vars.SITENAME currently supports the test management plugins Zephyr, Zephyr Essential and Xray.
If Zephyr (Scale) is selected for Jira Cloud, refer to the Zephyr connector documentation..
Consider this only if you want to read field values from additional third-party Jira plugins. Enter the unique plugin schema initials as a comma-separated list.
\* Example: For the Elements Connect plugin, if schema is com.valiantys.jira.plugins.SQLFeed:SQLFeed;fe09876hjgftp0912 add schema initial as com.valiantys.jira.plugins.SQLFeed.
To identify the plugin schema initials, refer to the Jira Create Metadata API (/createmeta). In the API response, locate the schema attribute for the required field.
(See Jira REST API documentation for Create Metadata for details.)
- If Jira supports multiple plugins with similar schema prefixes, ensure you select the unique schema initials for the plugin whose field values need to be read.
- After specifying the schema initials, enter the corresponding field display name in the Plugin Fields Display Name section.


space.vars.SITENAME` with advance mapping.
Advance mapping can be done by following the steps given below:
* Edit the field mapping for which you need to map such fields.
* Expand the pop-up by clicking the arrow icon.
* Click  to change the default behavior of a particular field mapping.
* Place advance mapping in this field (There are some examples given below, use them as per your needs).
* Save.
This field will be considered as an array of String that holds the primary and child values in ordered position where index 0 will hold the primary value and index 1 will hold the child value. In this example 'TargetField' is a hierarchy (cascade) field in the target system that accepts array of String.'SourceField' is a hierarchy (cascade) field of source system that accepts array of String.
#### Example: hierarchy (cascade) field to hierarchy (cascade) field
```xml
space.vars.SITENAME }}
2. Change workflow configuration in Jira for sync user
**1. Add/Edit Workflow transition XML in Mapping configuration of {{** space.vars.SITENAME **}}**
Click [Workflow Transition](https://docs.opshub.com/v7.215/integrate/configure-integrations/mapping-configuration#workflow-transition) to learn when and how to configure workflow transition xml mapping. With this option, space.vars.SITENAME makes the required intermediate status transition automatically as per the transition(s) configuration on the end system.
**2. Change workflow configuration in Jira for sync user**
Jira allows user/role base transition(s) configuration. Use this configuration to configure any-to-any transition(s) for the integration user on Jira. Workflow transition(s) mapping is not required to be configured in space.vars.SITENAME if any-to-any transition(s) is configured. With this option, space.vars.SITENAME will be able to perform direct transition of the state field to the desired state as this option works when any-to-any transition is configured for an integration user. For step-by-step instructions for configuring any-to-any transition refer: [Configuration to allow all transitions](#configuration-to-allow-all-transitions).
#### Known Limitation
* The synchronization of Jira **workflow transition configuration** is not supported by space.vars.SITENAME.
### Inline attachments synchronization
For Fields having **Wiki Style Renderer** enabled, Jira allows to add inline attachments that can be images or any other type of files. Such content can be synchronized for Jira with the following behavior:
* For Jira fields, where inline attachments synchronization is being used, **Detect Conflict** should be kept OFF/Disabled in field mapping
* Below is the synchronization behavior:
* **When Jira is the source system** Images and other type of files are synchronized to the target system depending on whether the target system supports inline images or not. If the target system supports inline images, all inline files, for example, images or other type of files, are added as attachments for the target entity. Inline image are directly visible and other type of files are visible as href link in the field content.
* **When Jira is the target system** By default, Jira field comes as a **Text type** field when generating mapping, even if it has **Wiki Style Renderer** enabled. So, to synchronize inline images/attachments to Jira from other systems and supporting inline images, an advance mapping is required.
Given below is a sample advance mapping for Jama to `JIRA_Custom_Field` (Any custom Text type of field in Jira) for synchronization with wiki formatting:
```xml
space.vars.SITENAME will translate and synchronize those entity link references which are matching following text format as per mention sync option configured in mapping.
* When field is of Type Wiki and Jira is Cloud then space.vars.SITENAME will translate those entity link references which are matching text \*\* \[link display|{jira-server-url}/browse/{project-key}-{entityId}|smart-link]\*\*
* For example Description: "Sample text \[space.vars.SITENAME will translate those entity link references which are matching text \*\* \[link display|{jira-server-url}/browse/{project-key}-{entityId}]\*\*
* For example Description: "Sample text \[space.vars.SITENAME will translate those entity link references which are matching text **{jira-server-url}/browse/{project-key}-{entityId}**
* For example Description is "Sample text" or Description is "Sample text"
* Click on [**Mention Sync Setting**](https://docs.opshub.com/v7.215/integrate/configure-integrations/mapping-configuration#mention-setting) to know more about entity mention mapping and synchronization behavior in general.
### Relationships
#### Zephyr(Plugin)
**Known Behavior**
* Zephyr link-related changes in Jira issues will synchronize during the next update of the Jira issue
* Reason:
* When creating or removing Zephyr-related links in a Jira issue, the issue’s 'updated' or 'modified' timestamp is not automatically changed.
* As a result, these link changes are not immediately recognized and will only be synchronized when the issue is next updated.
* To synchronize Zephyr link changes immediately, users must manually update the Jira issue (e.g., by editing a field or adding a comment).
**Known Limitation**
* Removing the relationship between a Jira issue and a Zephyr test execution is not supported.
* Reason: Zephyr API does not provide functionality for unlinking test executions
#### R4J Plugin
**Overview**
space.vars.SITENAME supports synchronization for R4J links \[R4J Child Link and R4J Parent Link] so that user can synchronize the relationship similar to how they are in R4J and can achieve the structure for Jira issues similar to what is visible in R4J view.
**Known behavior**
**Common \[Jira Cloud and on Prem]:**
* **When Jira is Source system**: If any change \[Add/Update/Remove] is made to the links \[R4J Child Link and R4J Parent Link], neither it updates the 'field name' of the entity nor it generates a revision. Hence, such changes will be synchronized to target system with next update \[which reflects on 'update on time'] on the entity.
* **When Jira is target system:**
* If an entity is to be added in R4J view through synchronization, but its Parent entity is still not synchronized through OIM or Parent entity details are not coming from source system, then this entity will not be visible in R4J view. It will only be visible when the Parent entity is synchronized through OIM and added to R4J view. The user can configure 'Default LInk' `` in case they want to bring such entities under a specific parent in R4J structure.
* For example, Target Lookup query for Default Link Configuration would be `id=@r4j_folder_id@`. Where the "r4j \_folder \_id" should contain the internal id of the folder which needs to be looked up. In case of root folder the id should be set to `-1_ROOT`.
* If entity is to be deleted from R4J view through synchronization, that entity will be shifted to Root folder \[i.e., a top most folder which is generally having same name as project name] within R4J view rather than its deletion from view. The removal from R4J view will remove the entity along with all its children from the view. If the user wants to add the removed entity back to the view, they will have to re-add all its child entities again. Hence, adding entity to Root level can save this trouble for user.
#### Web Link
**Overview**
* space.vars.SITENAME supports Web Link as External/Hyperlink for synchronization with Jira entities when Jira is Source and/or Target End point.
* In Relationship Mapping, **Web Link** link type needs to be selected for External Link Synchronization.
**Advance UseCase**
* Following is the working advance relationship configuration for the case when a Standard Link in source is mapped to Web Link in Target.
* For demonstration Jama Connector (does not support External Link) is considered as source and Jira (supports External Link) is considered as target.
* Given below is a **sample advanced mapping** for synchronizing linked entities of type **Defect** as **Web Link** along with additional properties.
```xml
space.vars.SITENAME
* Default Link Feature won't be supported in case of Weblink.
* For Weblink synchronization, in Relationship mapping User needs to map at least one Entity Type pair as its mandatory. This Entity Type mapping won’t have any impact on Web Link synchronization.
* Relationship Mapping for Web Link (as Source) to Standard Link (as Target) won't be supported. \[ {{fullurl:OH-Connector-0078 }} Link To Error Doc ]
**Stagil Assets Link**
**Overview**
* space.vars.SITENAME supports Stagil Assets links bidirectional synchronization.
* In relationship mapping, Stagil Assets link types need to be mapped for link synchronization.
**Known behavior**
* From Jira UI, the Stagil Assets links are visible in custom fields. However, these custom fields are supported as link types in space.vars.SITENAME.
* The Stagil Assets links will be synchronized based on current state only.
* Reason: API limitation.
#### Rank (R4J Plugin)
* Jira R4j Plugin allows to organize the issues in tree structure through **R4J Child Link** and **R4j Parent Link** relationships. The **R4J Child Link** relationship represents the child issues of the issue and **R4J Parent Link** represents the immediate parent of an issue in Jira R4J view.
* To synchronize the issues maintaining the above structure, the user can configure the **R4j Child Link** and **R4j Parent Link** relationship as per the standard [relationship configuration](https://docs.opshub.com/v7.215/integrate/configure-integrations/mapping-configuration#relationships) Within this structure, to maintain the rank of issues, the user should enable the Rank Synchronization as described in [Rank configuration](https://docs.opshub.com/v7.215/integrate/configure-integrations/mapping-configuration#configuration) section.
**Known Limitations**:
* The 'Folder' entity(which is part of structure within Jira R4j) is not supported as of now.
* Hence, the tree structure will be considered except for the 'Folder' entity. Although, that structure will be considered, which is within the 'Folder' entity.
* Therefore, the Rank Synchronization feature is supported for all Jira issues except for the 'Folder' entity.
* When Jira is source end system in synchronization:
* In Jira R4j, when a rank is changed for any issue, neither its **Updated** time is changed nor revision gets generated. Once the operation of the rank change is performed, it is reflected in the target end system upon the next update on the issue, which leads to the change in the **Updated** time of the issue.
#### Mapping for Archive Configuration
* When Jira Data Center is the target system, the Archive operation is performed by default in the synchronization of the [Source Delete event](https://docs.opshub.com/v7.215/integrate/advanced-sync-scenario/source-delete-synchronization).
* After the Archive operation is performed by space.vars.SITENAME in Jira, the entity will be archived in Jira.
* To only enable the Logical Delete operation in the target, "OH Archive" field should be mapped with the default value, "No" in the [Delete Mode](https://docs.opshub.com/v7.215/integrate/configure-integrations/mapping-configuration#delete-mode) mapping.
### Mapping limitations
If you have mapped custom fields, then:
* No two fields should have the same display name.
* No custom fields should have a display name which is also the internal name of any system field.
* No custom field should have a display name as 'Fix Version', 'fixVersions', 'Version', 'versions', 'Component' or 'components'.
Jira allows users to translate issue types or fields name through Jira User Interface or using external plugins. However, there are certain behavioral limitations with such translations, which are listed below:
* In case user has translated the issue type's name from 'Epic' to 'Feature'. So, the label 'Issues in Epic' will be translated to 'Issues in Feature' on Jira UI. But in space.vars.SITENAME, mapping configuration for Issue Relationship, the link type will still remain/labeled as 'Issues in Epic'.
* If a field is part of a synchronization and the user translates it later, then that field needs to be re-mapped in the mapping configuration.
* Fields named **Status Category Changed** and **Status Category** were added as system fields in the On-Demand Jira version. We are checking with Atlassian team for more details, such as data type and values for these fields. As of now, synchronization of these fields is not supported.
If any text type field is mapped for entities which do not support history in a bidirectional integration, additional revisions might be synchronized to the other system. To resolve this issue, the text field should be trimmed in advance mapping configuration while writing to Jira.\_
If you have enabled either Zephyr or Xray Plugin for Jira either as source or target system in space.vars.SITENAME and mapped field of type **steps/iterations** during field mapping, then you should be aware of the following limitation:
* For fields of data type **steps/iterations**, space.vars.SITENAME does not support an auto conversion of rich text content like HTML or Wiki content as per data type of target mapped field unlike supports for HTML or Wiki type of field(s). Hence when this type of field is mapped either as the source or target end point, then space.vars.SITENAME shows the following warning "Rich text content of HTML or Wiki type of field will not be synchronized to target end point in the correct format." It means that the formatted text is either sync in target along with tag or is rendered in a different format. So, to retain the Rich Text content in the target end point, it is required to perform an advance mapping for the content of steps that could be of types like HTML or Wiki. Advance mapping differs as per the content type of source and target end system for the mapped field. \*
1. Given below is a **sample advanced mapping** from Jira to RALLY for synchronizing **Manual Steps** of **Xray entity** along with formatting:
```xml
space.vars.SITENAME.
**Criteria samples**
| **Field Type** | **Criteria Description** | **Criteria Snippet** |
| ------------------- | ------------------------------------------------------------------------------------------------- | ---------------------------------------------- |
| **Lookup** | Synchronize all entities which have certain value in Lookup | `Priority = "Critical"` |
| **Date** | Synchronize all entities created after certain date | `created >= "2018-04-14"` |
| **Text** | Synchronize all entities which contains 'UI' in Summary field | `summary ~ "UI"` |
| **User** | Synchronize all entities which was created by user 'Robert' | `creator = "Robert"` |
| **User and Lookup** | Synchronize all entities which was created by user 'Robert' and also has 'Priority' as 'Critical' | `creator = "Robert" and Priority = "Critical"` |
| **Lookup or Text** | Synchronize all entities which has Priority as 'Critical' or has 'UI' as text in 'Summary' field | `Priority = "Critical" or summary ~ "UI"` |
### Target LookUp Configuration
Provide Query in Target Search Query field such that it is possible to search the entity in the Jira as a destination system. In the target search query field, you can provide a placeholder for the source system's field value in the `@` symbol.
Go to **Search in Target Before Sync** section on [Integration Configuration](https://docs.opshub.com/v7.215/integrate/configure-integrations/integration-configuration) page for more details.
For example there is an use case to search an entity in Jira (Destination system), which has the entity id of the source system in a field named 'TargetCustomField'. The source system's entity id is stored in 'source\_system\_id'. If the Target Search Query is given as: TargetCustomField = "@source\_system\_id@", then while processing this query @source\_system\_id@ will be substituted with the value of source\_system\_id from the source system's entity and then the query will be made to Jira.
Given below are the sample snippets of how the JQL queries can be used as target entity lookup query in space.vars.SITENAME. For this example the id information of the source system entity id is stored in source\_system\_id
**Target lookup query samples**
| **Field Type** | **Target Lookup Use Case** | **Snippet** |
| ------------------- | ------------------------------------------------------------------------------------------------------------------------------------ | --------------------------------------------------------------------------------------------------------- |
| **Text** | Target lookup on the entity which has source entity's id in 'RemoteEntityIdFieldText' field | `"RemoteEntityIdFieldText" ~ "@source_system_id@"` |
| **Lookup** | Target lookup on the entity which has source entity's id in 'RemoteEntityIdFieldLookup' field | `"RemoteEntityIdFieldLookup" = "@source_system_id@"` |
| **Lookup or Text** | Target lookup on the entity which has source entity's id in 'RemoteEntityIdFieldLookup' field or in 'RemoteEntityIdFieldText' field | `"RemoteEntityIdFieldLookup" = "@source_system_id@" or "RemoteEntityIdFieldText" ~ "@source_system_id@"` |
| **Lookup and Text** | Target lookup on the entity which has source entity's id in 'RemoteEntityIdFieldLookup' field and in 'RemoteEntityIdFieldText' field | `"RemoteEntityIdFieldLookup" = "@source_system_id@" and "RemoteEntityIdFieldText" ~ "@source_system_id@"` |
#### Target Lookup Query for R4J Folder Entity
* space.vars.SITENAME supports target lookup query on folder internal id.
* Target lookup query format is id=@other\_system\_field\@. Where the "other\_system\_field" is a field in the source system and should contain the internal id of the folder which needs to be looked up. In case of root folder the id should be set to -1\_ROOT.
#### Target Lookup for Zephyr Entities
Target Lookup is supported for **Test**, **Test Cycle**, and **Test Execution** entities when Jira's deployment type is **Cloud**.
* **Test Entity** Refer to [Target LookUp Configuration](#target-lookup-configuration)
* **Test Cycle Entity**
* Target lookup on cycle internal ID
* Format: `id=@cycleId@`
* Refer to [Find Test Cycle Id](#find-test-cycle-id)
* **Test Execution Entity**
* Limited parameters supported
* Example: `executionStatus=@State@`
* [Zephyr ZQL Parameters](https://support.smartbear.com/zephyr-squad-cloud/docs/execute/zql.html)
#### Target Lookup for QMetry Entities
Target Lookup is supported for **Test Case**, **Test Run**, **Test Scenario**, and **QMetry Test Execution** entities.
* **Test Case, Test Run, and Test Scenario** Refer to [Target LookUp Configuration](#target-lookup-configuration)
* **QMetry Test Execution Entity** Example:
```json
{
"Test Run": {
"key": "summary",
"operator": "~",
"value": "'@Name@'"
},
"Test Case": {
"key": "key",
"operator": "=",
"value": "@Remote ID@"
}
}
```
### Add comment interval
* In case the number of comments to be synchronized to Jira is high or you observe issues with ordering of comments in Jira, you can define an interval (in milliseconds) to be added between addition of two comments in Jira.
* To add this interval, please navigate to **Override parameters for write operations(Destination)** in Entity level advance configurations.
* As shown in below image, please specify the interval (in milliseconds) in field **Jira add comment interval**. The maximum acceptable value for this field is 2000 (milliseconds).
* Default value for this field is 0 milliseconds.
* Even though you specify this interval in **Jira add comment interval** field, it will be added only when there are multiple comments to be added to Jira and the time difference (in milliseconds) between the last comment added and the current comment is less than the interval specified in the field. For single comment, this interval won't be added.
* Please use this field only if absolutely necessary since it will impact overall performance.
### Fetch Mapped Data Only
If you want to fetch only those fields and data which are used in mapping configurations for synchronizing an entity between Jira and the other system to be integrated, you can use the **Fetch Mapped Data Only** feature. Go to **Fetch Mapped Data Only** section on [Integration Configuration](https://docs.opshub.com/v7.215/integrate/configure-integrations/integration-configuration) page to learn in detail about this configuration.
### Integration limitations
* Jira allows users to translate issue types or fields name through Jira User Interface or using external plugins. However, there are certain behavioral limitations with such translations, which are listed below:
* History synchronization will not be maintained for the changes done prior to the last translation, for the translated fields/Link type.
* OIM does not support projects with `" and \` characters in their project names.
* Jira version 8.7.0 onwards, [user can be anonymized](https://confluence.atlassian.com/adminjiraserver/anonymizing-users-992677655.html). So \*\* space.vars.SITENAME\*\* can't synchronize data of such users based on their information that existed before user was anonymized. For example: If a Jira user 'John Doe' was anonymized, Jira will convert its username to an alias such as 'jirauser1001'. Hence, email or user-based lookup won't work for user fields with such user value.
* When R4J plugin is enabled for your project, an additional field named **Path(R4J)** will be available (as a ReadOnly Field) for synchronization. Editing this field will be only synchronized to target with Next Update on Issue which modifies Issue's 'Updated'.
* In Jira, if the project key of the project \[configured for synchronization] has been changed, \*\* space.vars.SITENAME\*\* server needs to be restarted.
* When Jira is the source system and Jira's deployment mode is **Cloud**:
* Synchronization of **Child issues** link type is not supported.
* Reason: API limitation
**Entity specific information**
### Sprint entity
In case of Sprint entity:
* There are two lookup fields available for mapping the boards:
* **Origin Board ID**
* **Origin Board Name**
* \*\* space.vars.SITENAME\*\* allows for the selection of either field separately, but not both concurrently.
* If you have unique board names, it is easy to use the Origin Board Name field for mapping as you can directly match the board name without the need for additional value mapping.
* However, if there are multiple boards with the same name, you can use the Origin Board ID field, which contains values in form of `"BoardId:::BoardName"`, uniquely identifying the boards based on their ID.
* Select boards from the list for which Sprints will be polled and synchronized to the target system. For doing so:
* Select the **Entity level mandatory settings** 
* From the advanced configuration, search and then select the boards for which the sprint needs to be synchronized.
* When `-All Boards-` has been selected then all sprints of all boards will be polled and synchronized to the target system.
### Folder(R4J) entity \[Jira On Premise]
#### Overview
* The [R4J plugin](https://easesolutions.atlassian.net/wiki/spaces/REQ4J/pages/5406729/User+Guide) allows user to organize entity within Folder to achieve a tree structure for Jira issues.
* \*\* space.vars.SITENAME\*\* supports synchronization of this Folder entity \[which will be visible as entity type `Folder(R4J)` while user is configuring an integration with Jira system].
* The entity type `Folder(R4J)` will be visible only for Jira on-premise instances.
* To achieve the tree structure, through synchronization user needs to configure the [Relationships (R4J Plugin)](#relationships-r4j-plugin) and [Rank (R4J Plugin)](#rank-r4j-plugin) as well.
#### Root Folder synchronization
* When R4J plugin is enabled in a project, a root folder with the same name as the project is automatically created and visible on Jira R4J view.
* The root folder ID in \*\* space.vars.SITENAME\*\* is `-1_ROOT`.
* \*\* space.vars.SITENAME\*\* synchronizes the root folder similar to any other folders available/created within R4J. In below example, 'TestR4J' is a Root Folder and rest are the custom folders created by User.
* If no new entity needs to be created in the target corresponding to the root folder, then, one can configure target lookup query in the target system to synchronize the root folder with the existing entity in target. The structure will be created as shown below.
#### Prerequisites
* `Folder(R4J)` entity will be only available for synchronization if R4J plugin is enabled for project. To enable R4J plugin for your project please refer [steps](https://easesolutions.atlassian.net/wiki/spaces/REQ4J/pages/40599560/Managing+Projects).
#### Known limitations
Below functionality is not available for Folder(R4J) on end system itself, hence they are not supported for synchronization:
Comment
* Synchronization of below functionality is not supported due to API limitations/issues:
* History/Revisions, Criteria-based synchronization, Inline image, Numbering values (*To understand what does numbering mean for a folder please refer* [R4J Folder numbering\_](#r4j-folder-numbering)).
* Target Lookup is supported only on Folder internal ID and `=` operator. For more information refer [Target lookup query for R4J Folder Entity](#target-lookup-query-for-r4j-folder-entity). Limitations of relationship between Folder(R4J) entity and Jira issues:
* From Issues synchronization, **Cross Project relationship is not supported**. So if an Issue is added/linked into a Folder of a different Project, synchronization will consider the folder of same project \[Corresponding ID of same project will be considered]. To avoid such issue, you can synchronize the relationship from Folder synchronization.
* For synchronization of Relationship from Issues, the Issue needs to be updated. Other Limitations:
* The statistics of child issues status and issue types available within folder is not supported currently.
### Worklog entity
Jira's time tracking feature enables users to record the time they spend working on issues by creating worklogs.
#### Ways to sync worklog
**Sync worklog as fields of the parent entity**
If you want to sync worklog as fields of the parent entity, then use the following fields during field mapping of the parent entity:
| **Worklog Field Name** | **Data Type** | **Is Read-Only?** | **Description** |
| ---------------------- | ------------- | ----------------- | ------------------------------------------- |
| Original Estimate | Timeunit | No | Time estimated to complete the work |
| Remaining Estimate | Timeunit | No | Hours left to complete the work |
| Time Spent | Timeunit | No | Time spent working on one Worklog |
| Worklog Author | User | Yes | User who logged the work |
| Worklog Date Started | Date | No | Date to start tracking time spent on issues |
| Worklog Date Created | Date | Yes | Date when Worklog was created |
| Worklog Date Updated | Date | Yes | Date when Worklog was updated |
> **Note**: Turn off the **Conflict Detection** flag for these fields and turn on the **Overwrite** flag when configuring field mapping.
**Known Limitation of this approach**
* Conflict Detection will not work on worklog fields.
* Overwrite flag should be turned on for worklog fields during field mapping configuration.
* In this approach, Worklog fields are not synchronized one-to-one, but an overall roll-up effect is maintained. This means the total time spent will be matching the parent entity level.
* This approach can be used only for **uni-directional sync**. Bi-directional sync with this approach may result in inconsistent state in end-systems for worklog-related data.
* Update on worklog fields will be synchronized only when there is change in **Time Spent** field. This means, updating only worklog author will not trigger any update.
**Sync worklog as different entity**
Worklog is a dependent entity; therefore, it always requires a parent entity. So, field mapping and integration configuration need to be done as described in the subsequent section.
#### Field mapping and integration
If you want to sync worklog as a different entity then use the following fields during field mapping of worklog entity:
| **Worklog Field Name** | **Data Type** | **Is Read-Only?** | **Description** |
| ---------------------- | ------------- | ----------------- | --------------------------------------------------- |
| Worklog Create Author | User | Yes | User who logged the work |
| Worklog Date Created | Date | Yes | Date when Worklog was created |
| Worklog Date Started | Date | No | Date to start tracking time spent working on issues |
| Worklog Date Updated | Date | Yes | Date when Worklog was updated |
| Projects | Lookup | No | All Jira projects accessible to user |
| Time Spent | Timeunit | No | Time spent working on one Worklog |
| Worklog Update Author | User | Yes | User who updated the work |
| Work Description | Text | No | Description of logged work |
| Worklog.Parent | Text | Yes | Display id of worklog's parent entity |
> When it is required to sync the worklog as different entity, Jira mandatorily asks for parent entity. For this mandatory requirement, we need to do the parent linkage during mapping creation as given in the screenshots below.

> During integration configuration when **worklog** is selected as the entities to sync, choose **Entity level mandatory settings** to select parent entity/entities whose Worklogs need to be synchronized.
 
#### Synchronize Deleted Worklogs
Create a separate field mapping for synchronizing deleted worklogs with only one field, such as **Time Spent**. Please do not map other fields. Change the workflow related configuration of the integration by going to **Workflow Association** of **Entity level mandatory settings** as shown in the screenshot below.
#### Known Limitation of this Approach
* Worklogs do not support Criteria configuration.
* 'Delete Worklog' is not supported for Jira as a target system.
* Jira accepts only positive numbers for **Time Spent** field. Sync will result in failure when `0` or negative values are passed.
* Deleted worklogs will synchronize only after some other update.
* Synchronization of deleted worklogs is supported for versions greater than or equal to 7.0.0 due to Jira's API limitations. It means, worklog efforts will not match for Jira versions older than 7.0.0. We recommend not to delete the worklogs or not to upgrade to newer versions.
#### Default Behavior
* When Jira is the target system, worklog will be created by the integration user.
* If **Worklog Start Date** is not mapped and Jira is the target system, time tracking will start from the current date and time.
### Zephyr Plugin Entities
* space.vars.SITENAME supports three Zephyr entities: Test, Test Cycle, Test Execution, Folder.
* The supported versions of Zephyr plugin with ZAPI plugin are specified in Systems Supported List).
> **Note** For Zephyr Cloud, ZAPI plugin is not required.
#### Prerequisites
**Synchronization of Zephyr entities with Zephyr plugin version 5.4.0.x and above**
* **Applicable When:** If integration is configured with an instance of Jira system (with Zephyr plugin version 5.4.0.x and above) for **Test Cycle** entity.
* **Reason:** There has been sorting related changes in Zephyr plugin due to which some specific changes are required in Zephyr's general configuration. For more details, refer to [Zephyr 5.4.0 Release Notes](https://zephyrdocs.atlassian.net/wiki/spaces/ZFJ0500/pages/1061421110/All+Release+Notes)
* **Actions:** Change the configuration for Zephyr plugin in Jira and set option **Sort cycles and folder order** to **Custom order**. Refer to this document: [Reorder Test Cycles and Folders](https://zephyrdocs.atlassian.net/wiki/spaces/ZFJ0500/pages/1247739905/Reorder+Test+Cycles+and+Folders#Change-Reorder-Option)
**Synchronization of Zephyr Cloud entities**
* SmartBear provides \[a jar] for the authentication of Zephyr entities via JWT token. Follow the steps below for placing this jar in OpsHub Installation Directory:
* Navigate to `Mapped Entity Type
\[Link From]
Entity Type in Relationship Configuration
\[Link To]
space.vars.SITENAME.
* Write side support for attachments in the **Step Results** field (part of the **Test Execution** entity) is not available.
* To synchronize custom fields in Zephyr Cloud, custom field id is required.
* **Reason**: Zephyr doesn't provide an API to get the custom field details. Therefore, user needs to provide custom field id to synchronize custom fields. Refer to [Find Zephyr Custom Field Id](#find-zephyr-custom-field-id) section for the custom field ids.
* To synchronize custom fields of Test Execution entity, refer to [Synchronize Custom Fields of Test Execution](#test-execution) section.
* To synchronize custom fields of Test Steps (field of Test entity), refer to [Synchronize Custom Fields of Test Steps](#test-steps) section.
* Due to API limitation, if the project configured in integration has more than 10000 Test Execution entities, space.vars.SITENAME will only synchronize the first 10000 entities based on creation date of the Test Execution entity.
* **Folder(Zephyr) entity**
* Target lookup is not supported for Jira cloud. Criteria, Target and Remote Link sync are not supported for Jira on premise.
* Reason: Zephyr API unavailability.
* Default Link Configuration for link type **Test Cycle Linkage** is not supported.
* **Sprint Id** field synchronization is not supported.
* Folders can be moved across different Test Cycles in Zephyr. However, the synchronization of the movement is not supported by space.vars.SITENAME. Hence, if any folder movement will occur, then the synchronization will be failed.
### Xray plugin entities
* space.vars.SITENAME supports following Xray entities:
* For self-managed system: Test, Test Set, Test Plan, Test Execution, Sub Test Execution, Pre-Condition.
* For cloud system: Xray Test, Test Set, Test Plan, Test Execution, Test Run, Precondition.
* The supported versions of Xray plugin are specified in Systems Supported List.
#### Jira Self-managed Instance
**Test Entity**
* In Jira Xray, the \[space.vars.SITENAME. This is default behavior of Xray plugin which can be changed using the advanced mapping as described [below](#turn-off-auto-creation-of-folders-repository) .
**Turn off Auto-Creation of Folders/Repository**
\*If the user wants to turn off the auto-creation of the repository in the target system, he/she needs to make a few changes in the advanced xsl. Scenarios and steps applicable for each scenario are mentioned below:
* **Scenario 1:** For turning off the auto-creation of test repositories, the user can check if the test repository path exists on Jira(Xray) side or not. Based on that, the user can set the value for test repository path. On the contrary, if the path does not exist, the user can use the default repository path. A sample [Advance mapping](https://docs.opshub.com/v7.215/integrate/configure-integrations/mapping-configuration#view-edit-xslt-configurations-options) for similar case that can be tweaked as required is given below:
```xml
space.vars.SITENAME, the user can map the 'Manual Test Steps' field.
**Changes required to synchronize Manual Test Steps**
* When Jira is the source system, a change is required in the advanced mapping of the Manual Test Steps field to synchronize test steps attachments. The steps are given below:
1. Click the  icon of Test Repository Path field to open its [advanced xsl](https://docs.opshub.com/v7.215/integrate/configure-integrations/mapping-configuration#view-edit-xslt-configurations-options).
2. Replace the following line: \space.vars.SITENAME`.
**Xray Test Entity**
* In Jira, Xray Test is a test case. It can be of three types: Manual, Generic or Cucumber. The manual test case can be composed of multiple steps, and each step can contain actions, data & expected results.
* The manual test steps can be synced through the `steps` field available on the `space.vars.SITENAME` field configurations. Refer to [Mapping limitations](#mapping-limitations) section for reference.
* The calculated value for the status of the Xray Test entity can be synchronized through the `OH_Xray_Test_Status` field, available on `space.vars.SITENAME`'s mapping configuration screen.
* Test Repository paths can be synced using the `folder` field available on the `space.vars.SITENAME` field configurations.
**When Xray entity is the target system:**
* The `folder` is a lookup field and user can do one-to-one mapping if the repository path is available in the target system. If the repository path is not available, it will be created in the end system and a test entity will be linked to it.
* To ensure smooth and accurate synchronization of test step results, the `OH_Test_Step_Id` field must be populated in the test case before syncing step results. This step is crucial for correctly mapping and updating step-level results to Xray.
**Test Run Entity**
* In Jira, Test Run is used to sync the test case execution results.
* To sync the step level results in case of the manual test steps, user must configure the `iterations` field available on the `space.vars.SITENAME` field configurations.
**Known Limitations**
* **Due to API limitation:**
* Synchronization of the 'Parameter' (which can be used in the 'steps' field in Xray Test entity) is not possible.
* Synchronization of the Sub Test Execution entity is not supported.
* Iteration level status update synchronization is not supported as of now for Test Run entity when the test type is Generic or Cucumber.
* **When Jira \[Xray] is source system:**
* For Xray Test, Test Execution, Test Set, Test Plan and Precondition entities, criteria will not work on Xray fields. Criteria can be given only on Jira fields as JQL query for these entities.
* Criteria is not supported for Test Run entity.
* For all the Xray fields, only current values (present at the time of synchronization) will be synchronized. Historic (Audit/Revisions) values will not be synchronized to target system.
* An additional update to any Jira field is required in the following cases:
* Any Xray field updated in the source system.
* When an attachment is added to a test step with manual test type.
An additional update is required because the history is not generated by Jira when the Xray's specific fields are updated in Jira.
* Test Run entity will be synced without history.
* **When Jira \[Xray] is target system:**
* If an in-flight failure occurs for the Xray fields during an Xray Test, Precondition, Test Plan, Test Set, or Test Execution entity synchronization, `space.vars.SITENAME` will overwrite the data in the target system. Therefore, it is necessary to enable conflict resolution for these fields to ensure proper synchronization.
* Below links are not supported for create & update. They are only available for read operation:
* Test Run entity – link types: Xray Test & Test Execution
* Test Execution entity – link types: testRuns
* Xray Test entity - link types: testRuns
* For syncing the `Test Run` entity's step Results, the user should create below custom field of type `Text (Single Line)` with the specific given name in the Xray Test Step which is: `OH_Test_Step_Id`. Refer to [Project Settings: Test Step Fields](https://docs.getxray.app/display/XRAYCLOUD/Project+Settings%3A+Test+Step+Fields) section for details.
* For syncing the Test Run, this custom field of type `Text (Single Line)` needs to be created in the Test Run: `OH_Last_Update`. Make sure to select all the test types in the `Test Type` selection while creating this field. Refer to [Project Settings: Test Run Custom Fields](https://docs.getxray.app/display/XRAYCLOUD/Project+Settings%3A+Test+Run+Custom+Fields) section for details.
* For Xray Test, Test Execution, Test Set, Test Plan and Precondition entities, target lookup will not work on Xray fields. Target lookup can be given only on Jira fields as JQL query for these entities.
* Target lookup is not supported for Test Run entity.
**Known Behavior**
**When Jira \[Xray] is target system:**
* To synchronize the `steps` of the `Xray Test` entity, the `testType` field of the Xray Test must be set to `Manual` type.
* **Reason:** Test steps can only be added in the Xray Test from UI and API when the test type is set to Manual.
* For Test Run synchronization, the user must configure `Xray Test` & `Test Execution` links and sync these entities (associated with Test Run) before running Test Run integration. Without it, the syncing process cannot be completed.
* For Test Run entities, in `iteration` field, step result `Defects` type of links from source will be synced at the entity level in target system.
* For `Xray Test` and `Test Run` entities, step-level inline attachments/images will be synced at entity level when Jira is the target system.
* For `Xray Test` and `Test Run` entities, step-level attachments will be synced at entity level when Jira is the target system.
### QMetry plugin entities
* `space.vars.SITENAME` supports four QMetry entities: Test Case, Test Scenario, Test Run, QMetry Test Execution (Only for QMetry Self-Managed).
* For the supported versions of QMetry plugin, refer to \[../supported-connectors/systems-supported.md].
#### Supported Relationships
Following are the relationships that are supported for **QMetry Self-Managed** entities:
| **Mapped Entity Type** (Link from) | **Entity Type in Relationship Configuration** (Link to) | **Relationship Type** |
| ---------------------------------- | ------------------------------------------------------- | --------------------- |
| Test Scenario | Test Case | QMetry TestCase |
| Test Run | Test Case | QMetry TestCase |
| Test Run | Test Scenario | QMetry TestScenario |
| QMetry Test Execution | Test Case | QMetry TestCase |
| QMetry Test Execution | Test Run | QMetry TestRun |
#### Default Behavior
* When Jira is the target system in space.vars.SITENAME, to synchronize the QMetry Test Execution, either Target Lookup or 'QMetry TestCase' linkage with Test Case Entity, and 'QMetry TestRun' linkage with Test Run Entity must be configured.
#### Criteria Configuration
**Test Case, Test Run, and Test Scenario entities**
* Criteria feature is supported for Test Case, Test Run, and Test Scenario entities.
* For more information on how to synchronize Test Case, Test Run, and Test Scenario entities based on criteria, refer to [Criteria Configuration](#criteria-configuration) section.
#### Target Lookup
For Target Lookup configuration of QMetry entities, refer to [Target lookup for QMetry Entities](#target-lookup-for-qmetry-entities) section.
#### QMetry Known Limitations
* When QMetry plugin is enabled, ensure you do not have issue-types with the names **Test Case**, **Test Run**, or **Test Scenario** in Jira as they would conflict with QMetry entities' names.
* To synchronize the changes in test steps field, update some basic fields in Jira.
* To get the changes synchronized in QMetry linkages, update some basic fields in Jira.
* For QMetry Test Execution:
* When Jira is the source system in space.vars.SITENAME:
* Synchronization is not supported.
* When Jira is the target system in space.vars.SITENAME:
* Synchronization of step level result, Bug linkages are not supported.
* [Target LookUp Configuration](#target-lookup-configuration) is only supported to find the unique Test Execution Id.
### AIO plugin entities
* space.vars.SITENAME supports three AIO entities: AIO Test Case, AIO Test Cycle, AIO Test Run.
* The supported versions of the AIO plugin are mentioned in [Systems Supported List](https://docs.opshub.com/v7.215/systems-supported).
#### Supported Relationships
Following are the relationships supported for **AIO** entities:
| **Mapped Entity Type** \[Link from] | **Entity Type in Relationship Configuration** \[Link to] | **Relationship Type** |
| ----------------------------------- | -------------------------------------------------------- | -------------------------------------- |
| AIO Test Case | Entity (Any Jira issue type) | Jira issue linkage |
| | Jira Sprint | Name of Custom Field for Jira Sprint |
| AIO Test Cycle | Entity (Any Jira issue type) | Jira issue linkage |
| | Jira Sprint | Name of Custom Field for Jira Sprint |
| | AIO Test Case | AIO Test Case linkage |
| | AIO Test Run | AIO Test Run linkage |
| AIO Test Run | Entity (Any Jira issue type) | Jira issue linkage |
| | Jira Sprint | Name of Custom Field for Jira Sprint |
| | AIO Test Case | AIO Test Case linkage (**Mandatory**) |
| | AIO Test Cycle | AIO Test Cycle linkage (**Mandatory**) |
| | AIO Test Run | Parent Test Run linkage |
| | AIO Test Run | Child Test Run linkage |
#### Criteria Configuration
**AIO Test Case and AIO Test Cycle entities**
* Navigate to Criteria Configuration section on [Integration Configuration](https://docs.opshub.com/v7.215/integrate/configure-integrations/integration-configuration) page to learn in detail about criteria configuration.
* Set the **Query** in JSON format. Refer to the sample snippets below to know how JSON queries can be used as criteria in space.vars.SITENAME.
**Criteria samples**
| **Field Type** | **Syntax for datatype** | **Description** |
| -------------- | ------------------------------------------------------------------------------------------------------------------------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| **Boolean** | `"fieldName" : { "value" : "true or false" }` | Pass the true or false for a Boolean field. |
| **Date** | `"fieldName": { "comparisonType": "EMPTY, BEFORE, AFTER, EQUALS, BETWEEN", "value1": "date or timestamp", "value2": "date or timestamp" }` | Dates can be specified either using Unix timestamp in milliseconds (e.g., `1574416800000`) OR using standard date time format (e.g., `2019-11-22T10:00:00.000Z` or `Fri, 23 April 2021 23:59:59 HST`). |
| **List** | `"fieldName" : { "comparisonType": "IN", "list": [ list of values ] }` | Pass the comma-separated values within the brackets. |
| **Number** | `"fieldName": { "comparisonType": "EMPTY, GREATER_THAN, LESS_THAN, EQUALS, BETWEEN", "number1": number, "number2": number }` | Use number values. `value1` is required for most operations, `value2` only for BETWEEN. |
| **Text** | `"fieldName": { "comparisonType": "EXACT_MATCH, CONTAINS", "value": "any text" }` | Pass text inside quotes. |
> Custom field format: `"customFields":[ { "name": "Custom field name", "value": JSON object }, "ID": ID of custom field ]`
#### AIO Test Case
* The criteria query can be applied on the fields mentioned in the below snippet:
```json
{
"key": {
"comparisonType": "IN",
"list": ["string"]
},
"title": {
"comparisonType": "CONTAINS",
"value": "Regression"
},
"folderID": {
"comparisonType": "IN",
"list": [5002, 5612, 5650, 5651]
},
"ownedByID": {
"comparisonType": "IN",
"list": ["string"]
},
"jiraComponentID": {
"comparisonType": "IN",
"list": [5002, 5612, 5650, 5651]
},
"jiraReleaseID": {
"comparisonType": "IN",
"list": [5002, 5612, 5650, 5651]
},
"statusID": {
"comparisonType": "IN",
"list": [5002, 5612, 5650, 5651]
},
"priorityID": {
"comparisonType": "IN",
"list": [5002, 5612, 5650, 5651]
},
"typeID": {
"comparisonType": "IN",
"list": [5002, 5612, 5650, 5651]
},
"tag": {
"comparisonType": "IN",
"list": ["string"]
},
"automationKey": {
"comparisonType": "CONTAINS",
"value": "Regression"
},
"automationStatusID": {
"comparisonType": "IN",
"list": [5002, 5612, 5650, 5651]
},
"requirementID": {
"comparisonType": "IN",
"list": ["string"]
},
"createdDate": {
"comparisonType": "BETWEEN",
"value1": "2019-11-10T07:30:00Z",
"value2": "2019-11-20T07:30:00Z"
},
"updatedDate": {
"comparisonType": "BETWEEN",
"value1": "2019-11-10T07:30:00Z",
"value2": "2019-11-20T07:30:00Z"
},
"isArchived": {
"value": "true"
},
"customFields": [
{
"name": "Environment",
"value": {
"comparisonType": "IN",
"list": ["string"]
},
"ID": 10113
},
{
"name": "Environment",
"value": {
"comparisonType": "IN",
"list": [5002, 5612, 5650, 5651]
},
"ID": 10113
},
{
"name": "Environment",
"value": {
"comparisonType": "BETWEEN",
"value1": "2019-11-10T07:30:00Z",
"value2": "2019-11-20T07:30:00Z"
},
"ID": 10113
},
{
"name": "Environment",
"value": {
"comparisonType": "BETWEEN",
"number1": 54,
"number2": 100.05
},
"ID": 10113
}
],
"ID": {
"comparisonType": "IN",
"list": [5002, 5612, 5650, 5651]
}
}
```
#### AIO Test Cycle
* The criteria query can be applied on the fields mentioned in the below snippet. Users can take the required field on which they want to apply the criteria as shown in the below snippet:
```json
{
"key": {
"comparisonType": "IN",
"list": [
"string"
]
},
"title": {
"comparisonType": "CONTAINS",
"value": "Regression"
},
"folderID": {
"comparisonType": "IN",
"list": [
5002,
5612,
5650,
5651
]
},
"jiraComponentID": {
"comparisonType": "IN",
"list": [
5002,
5612,
5650,
5651
]
},
"jiraReleaseID": {
"comparisonType": "IN",
"list": [
5002,
5612,
5650,
5651
]
},
"startDate": {
"comparisonType": "BETWEEN",
"value1": "2019-11-10T07:30:00Z",
"value2": "2019-11-20T07:30:00Z"
},
"endDate": {
"comparisonType": "BETWEEN",
"value1": "2019-11-10T07:30:00Z",
"value2": "2019-11-20T07:30:00Z"
},
"closeDate": {
"comparisonType": "BETWEEN",
"value1": "2019-11-10T07:30:00Z",
"value2": "2019-11-20T07:30:00Z"
},
"tag": {
"comparisonType": "IN",
"list": [
"string"
]
},
"taskID": {
"comparisonType": "IN",
"list": [
"string"
]
},
"isLockedForEdit": {
"value": "true"
},
"isClosed": {
"value": "true"
},
"isArchived": {
"value": "true"
},
"customFields": [
{
"name": "Environment",
"value": {
"comparisonType": "IN",
"list": [
"string"
]
},
"ID": 10113
},
{
"name": "Environment",
"value": {
"comparisonType": "IN",
"list": [
5002,
5612,
5650,
5651
]
},
"ID": 10113
},
{
"name": "Environment",
"value": {
"comparisonType": "BETWEEN",
"value1": "2019-11-10T07:30:00Z",
"value2": "2019-11-20T07:30:00Z"
},
"ID": 10113
},
{
"name": "Environment",
"value": {
"comparisonType": "BETWEEN",
"number1": 54,
"number2": 100.05
},
"ID": 10113
}
],
"ID": {
"comparisonType": "IN",
"list": [
5002,
5612,
5650,
5651
]
}
}
```
#### Known Behavior and Limitations
**Common**
* AIO Test Entities' read only is supported in space.vars.SITENAME.
* AIO Test Entities' history-based sync is not supported due to API unavailability.
* Comments and Attachments' sync are not supported.
**AIO Test Case**
* The sync of the relationship/links' changes requires the updating of any field of Test Case entity.
**AIO Test Run**
* For AIO Test Run, the sync of Executed Date/Time is not supported, as AIO does not provide any Execute Date/Time field from UI/API.
* Criteria-based sync is not supported due to API unavailability.
### Jira Service Management (Formerly known as Jira Service Desk) plugin entities
The configuration of Jira Service Desk is similar to Jira. The things that are different are listed in this section.
* In Jira Service Desk, there are 2 types of comments:
* **Share with customer**: This is referred as public comments in field mapping advance configuration of comments
* **Comment internally**: This is referred as private comments in field mapping advance configuration of comments
For getting more information regarding field mapping configuration, refer to the **Map Comments** section on [Mapping Configuration](https://docs.opshub.com/v7.215/integrate/configure-integrations/mapping-configuration) page.
**Known limitations** The known limitations for Jira Service Desk are:
**Related to SLA type of fields**:
* Jira Service Desk doesn't provide history for SLA type of fields. So, history state synchronization is not posisble for these fields. Also, as the historic values for SLA type of fields are not supported, conflict detection feature for SLA type of fields should be disabled during mapping configuration.
* Advance mapping should be done for polling properties of these fields.
**Related to Service Desk Request Status field**:
* Jira Service Desk doesn't provide history for **Service Desk Request Status** field. So, history state synchronization is not possible for this field. And, as the historic values for **Service Desk Request Status** field is not supported, conflict detection feature for this field should be disabled during mapping configuration.
### Jira Zephyr Scale Plugin
* The documentation for the Jira Zephyr Scale plugin is available at [Jira Zephyr Scale](https://docs.opshub.com/v7.215/connectors/jirazephyrscale) .
### Jira Elements Connect Plugin
* With Jira Elements Connect plugin, the user can add custom fields which uses data from external data sources.
* space.vars.SITENAME supports all the variations of the field types supported by Elements Connect.
| **Elements Connect Field** |
| -------------------------- |
| Live text |
| Live user |
| Snapshot text |
| Snapshot date |
| Snapshot datetime |
* Live text and snapshot text fields are considered as lookup fields in space.vars.SITENAME. To configure value mappings of these type of fields, enable "include field values in /createmeta response" option from the field's advanced configuration of Elements Connect.
* If the above option is not enabled in Jira, the fields can still be mapped in space.vars.SITENAME, but value mapping cannot be done. In such cases, space.vars.SITENAME will sync the exact same value as it is retrieved from the end system.
## Known behaviors and limitations
* Elements Connect plugin provides different types of fields such as radio button, check box, multi-select list, etc. However, all these types of fields will appear as multi valued fields in space.vars.SITENAME due to Jira API limitation.
* Read only fields:
* Read only fields will appear as writeable fields in space.vars.SITENAME.
* Reason: Jira does not provide any way to identify the read only fields. Additonally, Jira API allows to update read only fields.
* Single valued fields:
* Single valued fields will appear as multi valued field in space.vars.SITENAME.
* In this case, space.vars.SITENAME sends mutliple values to Jira but the Jira UI will show only a single value of the field. However, The reverse sync will work properly in this case.
* Reason: Jira does not provide any way to differentiate between single valued and multi valued fields. Additonally, Jira API allows to update single valued field with multiple values.
* Dependent fields:
* All the dependent fields are considered as Text type fields in space.vars.SITENAME and value mapping cannot be performed for these fields.
* In case value mapping is required, the advanced mapping can be configured in the space.vars.SITENAME.
* Reason: Jira API does not return lookup values for dependent fields even if the "include field values in /createmeta response" option is enabled in Jira.
* Data source as Jira REST API:
* In the below mentioned use case, the lookup values will not be loaded for the Elements Connect field. Hence, the user will not able to perform value mappings in space.vars.SITENAME.
* Jira REST API is used as data source for Elements Connect field. The authentication type configured in Jira system configuration form of space.vars.SITENAME is not cookie-based authentication. In such case, Jira API does not return any lookup values even if the "include field values in /createmeta response" option is enabled in Jira.
* It is recommended to configure the cookie-based authentication for value mapping in space.vars.SITENAME for Jira system. However, if the cookie-based authentication is not possible and value mapping is still required, here is an alternative way to use 'Jira REST API' as data source:
* Create a custom 'URL' data source having the URL field as the base URL of the in-built 'Jira REST API'.
* For the fields to be mapped in space.vars.SITENAME, select the above created custom Jira REST API data source from the drop down available in the fields configuration on Elements Connect's screen.
## Known Behaviours
### Dependent timespent field in status transition
* When the timespent field is mentioned as a dependent field in status transition XML in space.vars.SITENAME, the timespent field value only gets added in Jira due to its API. Hence, whenever a timespent value is provided as a dependent field, the field value gets increased cumulatively.
* For example, if the timespent field value of Jira is X, and the Y value is synced to that field, the final value of that field will become X+Y.
* However, due to Jira's timespent field behavior, it is recommended to set the default value for the timespent field as 0 in transition XML to keep the field value unchanged.
### Wiki Fields
* If there is any formatting that is present inside HTML `` tag, then that formatting will be converted into corresponding formatting inside wiki tag `{noformat}`. But, the formatting will not be rendered properly as per wiki `{noformat}` tag behavior, which doesn't allow adding any formatting inside `{noformat}`. Thus, the formatting will be displayed as part of content.
**For example -** For HTML text `Test No Format
`, the content "Test No Format" is displayed in bold style. It's corresponding wiki conversion is `{noformat}*Test No Format*{noformat}`. But, in Jira, the content will be displayed as "*Test No Format*" as the styling inside `{noformat}` is ignored by default.
* In HTML, we can indent the text inside `` or `` tag using `style=margin-left:40px` inside tag. Such leading indentation (using margin-left:40px) inside `` or `` tag will not be rendered in wiki format.
**For example -** For HTML text `Test No Format
`, This will indent the text "Test No Format" 40px to the right when viewed in HTML. Such indentation will not be rendered correctly in wiki format after HTML to wiki conversion.
* Any leading space gets trimmed by default from Jira rest api.
**For example -** Wiki text `" Test No Format"` → will be rendered as `"Test No Format"` (without space)
### For Team-Managed type of Projects in Jira Cloud
* User can't create single Integration for Multiple Projects synchronization \[i.e. Multiproject Integration]. Multi project integration can be configured for projects having same Templates \[i.e. Same/Shared Issue Types, Fields details etc...] whereas Team-Managed Project type is explicitly designed for teams who want to control their own working processes and practices in a self-contained space. Which leads to different configurations for different project as well as different entity types. Hence for Team Managed projects, user need to configure individual integrations for each projects as per their Template.
* To know which project type is currently being used, please refer this link: [How to check Project Type](https://support.atlassian.com/jira-service-management-cloud/docs/how-can-i-tell-if-im-in-a-classic-and-next-gen-project/)
### Duplicate Fields with Same Display Names in Jira
* In Jira, we can add a field with the same display name.
* When a field is added at project level and is configured on the create/edit screen:
* Only one field with the same name must be there on the create and edit screen.
* For the other fields at global level having the same names, the field's internal id will be appended to the field name.
* When a field is added at global level and is not configured with the project:
* The field's internal id will be appended to the duplicate fields with same display names.
### Issue linkages
* Jira allows users to define their own issue link types. This issue link types should have unique link names, but there are no similar constraint for inward and outward description.
* For example, here there are two issue link types 'Relates' and 'is related to' and both link type shared 'relates to' in inward/outward description
 * In this case following things are expected:
1. In relationship mapping screen you get unique list of all inward and outward description. Hence, relation configuration will only have one 'relates to' as link type which will be associated with both link type 'is related to' and 'Relates'.
2. When Jira is configured as source endpoint and linkages are fetched, all linkages that are under 'relates to' description will be synchronized to target. This includes linkages with link type 'is related to' and 'Relates'.
3. When Jira is configured as target endpoint, when adding link 'relates to' between two issues we'll add linking entity under 'Relates' link type and outward issue.
* As ordering system selects the link type that is first in admin panel. If first link type has same inward and outward name then linked item is added as outward issue.
4. When Jira is configured as target endpoint, when removing link 'relates to' between two issues we'll remove a linkage that comes first in as per ordering received from jira administration panel. We'll only remove one 'relates to' linkage.
## Known Limitations
* Impersonation is not supported in
* In this case following things are expected:
1. In relationship mapping screen you get unique list of all inward and outward description. Hence, relation configuration will only have one 'relates to' as link type which will be associated with both link type 'is related to' and 'Relates'.
2. When Jira is configured as source endpoint and linkages are fetched, all linkages that are under 'relates to' description will be synchronized to target. This includes linkages with link type 'is related to' and 'Relates'.
3. When Jira is configured as target endpoint, when adding link 'relates to' between two issues we'll add linking entity under 'Relates' link type and outward issue.
* As ordering system selects the link type that is first in admin panel. If first link type has same inward and outward name then linked item is added as outward issue.
4. When Jira is configured as target endpoint, when removing link 'relates to' between two issues we'll remove a linkage that comes first in as per ordering received from jira administration panel. We'll only remove one 'relates to' linkage.
## Known Limitations
* Impersonation is not supported in space.vars.SITENAME.
* Read Only fields in space.vars.SITENAME will not be writable due to end system API limitations/behaviours.
* E.g., Created date, Creator, Modified Date, Modified by, etc.
* To load all the custom fields associated with the selected project and issue type in space.vars.SITENAME mapping, there must be at least one entity present (of selected entity type in the given project of space.vars.SITENAME mapping) in Jira.
* In case, the above mentioned entity is not present in Jira, the fields associated with the create screen will only be loaded in space.vars.SITENAME mapping.
* Custom look up field must be present on create/edit screen to perform value mappings in space.vars.SITENAME.
* If the field is not present in create/edit screen, advanced mapping needs to be configured in space.vars.SITENAME to sync custom look up field values.
* "Sprint Details" field will be synced based on the current state only. Its historic values will not be synced due to the end system API limitations/behaviors.
* In Jira On-Premise, updating the mandatory "Sub Task Parent" link for the "SubTask" entity is not possible due to limitations in the REST API.
* It is recommended to configure "Sub Task Parent" link with the settings, **Fail if not found** and no default link. It ensures that incorrect link associations are avoided during entity creation via integration.
* Reason : Rest API Limitation
* For Jira Data Center 11.x and above, attachment synchronization will fail if the attachment name contains the `%` character.\
**Reason:** Jira DC 11.x+ no longer supports `%` in attachment file names
* Scoped API Token (Jira Cloud)
* Scoped API Token is supported only for Jira Cloud (Core Jira Software) — not for apps/plugins.
* When using a Scoped API Token, the Sprint field will not sync, and mapping this field will cause the sync to fail.
* Recommendation: Avoid mapping the Sprint field when using a scoped token.
* Reason: The required sprint api is not supported with scoped token.
## Troubleshoot
For "Link Issue" permissions, refer to document [OH-JIRA-0220](https://docs.opshub.com/v7.215/help-center-index/troubleshooting-index/errors-index/jira-error-solutions/oh-jira-0220) for errors and solutions.
## Appendix
### Add user
To add a Jira user:
* Log in into Jira as a user with the Jira Administrators global permissions.
* Click the **Administration** link on the top bar and select 'User Management'.
* On User Management page, click on 'Create User' button. This will display the **Create New User** form
* Enter the requisite details, such as Username, Password, Full Name and Email Address.
* Optionally, tick the **Send Notification Email** box to send the user an email containing: a. Their login name b. A link via which to set their password (this link is valid for 24 hours).
* Click the **Create User** button.
This will create the newly added user. For Jira Version Specific Guide, Refer [Managing Users - Atlassian](http://confluence.atlassian.com/display/JIRA/Managing+Users#ManagingUsersAddingaUser)
#### Assigning a user to a group
When a user is created, they will be added to all groups that are configured to have new users automatically added to them.
Steps to change a user's group membership:
* Log in into Jira as a user with the Jira administrators global permissions.
* Click the **Administration** link on the top bar and select 'User Management'.
* On User Management page, click on 'Users' option. This will display all the available users.
* Select the user for which the group membership needs to be changed.
* Click on 'Manage groups' button at the bottom right corner of the page.
* In the **Manage User Groups** section, you can select/deselect the groups that you want to associate/disassociate from the user's profile.
### Grant permissions to Jira user
Following are the steps to grant the permissions:
* Log in into Jira as a user with the Jira administrators role.
* From the top right corner, **Jira ADMINISTRATION** menu, select **Projects**.
* From the Projects list, select the project for which you want to grant permission.
* Click on 'Project Settings' at the bottom of the page.
* Click on 'Permissions' on the Project Settings page.
* Click the **Actions** button and select **Edit Permissions**.
* Click the **Grant Permission** link.
* Here select the permission and then select the attribute to which this permission is to be granted.
* For example select **Administer Projects** and select the user after choosing the **Single User** radio button as shown in the screenshot below.
* Click the **Grant** button.
### Grant access to Jira applications to a User
Before granting access or verifying that you have access, make sure you are logged in from the Admin account.
**For Jira on-premise instance:**
* To grant access or verify that a user has access to Jira Software or Jira Service Desk, click the **Settings** button and open the **User Management** tab.
* Navigate to the user you want to grant access to or verify access for.
* As shown in the screenshot below, verify that the user has access to **Jira Software**.
* If the user does not have the access to Jira Software, grant access by checking the checkbox.
**For Jira cloud instance:**
* Open **User Management** tab from **Settings**.
* Navigate to the user to grant/verify access.
* If the user doesn't have access, click the slider button to enable access.
### Grant Browse User Global Permission
* The group that includes the dedicated user should also have the **Browse Users** permission to access the usernames and e-mail ids of all available users.
* To enable this permission, navigate to **Systems** > **Global Permissions** > **Add Permission**
* Select **Browse User** and assign the permission to the group where integration user is present.
### Field Helper
You can use the Field Helper to determine why a custom or system field is not appearing on a screen.
* Log in with the dedicated integration user in Jira.
* Try to create an issue for the project/issuetype where the field is missing.
* Click **Where is my field?**
* Type the field name; the helper will guide you how to make it visible.
### Adding field to Screen
Steps to add a field to screen associated with a project:
* Select **Projects** > **View All Projects**
* Search and select the desired project
* Click
* Select **Screens** from the left nav
* You'll see screen associations for Create, Edit, View operations
* Select the screen to edit, scroll to the end and add the field
### How to check whether the field is not hidden from field configuration
1. Login to Jira as admin
2. Go to **Settings** > **Projects**
3. Choose the project
4. Click **Project Settings**
5. Click **Fields**
6. Click the pencil icon beside the field configuration
7. Check if the field is hidden
8. If yes, click **Show**
### Disabling Legacy Mode
Follow these steps:
* Click on Jira settings icon
* Select **Issues**
* From the left panel, select **Time tracking**
* Click **Deactivate** to disable Time Tracking
* Ensure **Legacy Mode** is disabled
* Click **Activate** to re-enable Time Tracking
### Server URL
* Log in to Jira as a user with the Jira administrators global permissions.
* Click the **Administration** link on the top bar and select **System**.
* From **General configuration**, get the **Base URL**.
### Custom field for Jira version < 6.2
To create a new custom field:
* Log in to Jira with Jira administrators global permissions.
* Click the **Administration** link on the top bar.
* Under **Issue Fields**, click **Custom Fields**.
* Click **Add Custom Field**.
* From the **Field Type** list, select the appropriate field. For space.vars.SITENAME, select **Read-only Text Field**.
* Click the **Next >>** button.
* Add a field name and optionally a description.
* Select **Free Text Searcher** as the **Search Template** for space.vars.SITENAME.
* Select applicable **Issue Types** or choose **Any issue type**.
* Select a **Project context** or use **Global context**.
* Click **Finish**, then associate the field with screens (at minimum, the Default Screen).
For details, refer to [Atlassian: Adding a Custom Field](http://confluence.atlassian.com/display/JIRA/Adding+a+Custom+Field)
### Database Information
* Log in to Jira with Jira administrators global permissions.
* Click the **Administration** link and select **System**.
* In the left menu, under **System**, click **System Info**.
* Under **System Info**, find **Database Type** and **Database URL**.
### How to Find Jira Version
* Log in to Jira with Jira administrators global permissions.
* In the left menu under **System**, click **System Information**.
* Under **Jira Info**, find the **Version**.
### Comma-Separated Values (CSV)
To format CSV field names correctly:
* **Commas** in field names: Use quotes. Example: `"Field Name2,with comma"`
* **Quotes** in field names: Escape using double quotes. Example: `"Field name3 ""with quote"""`
* **No escaping** needed for simple names: Example: `Field Name1`
* Full example combining all: `"Field Name1","Field Name2,with comma","Field name3 ""with quote"""`
### Configuration to Allow All Transitions
Steps to allow any-to-any state transitions:
1. Create a user group, e.g., `integration-users`.
2. Add the integration user to this group (see: [Assigning a user to a group](#assigning-a-user-to-a-group))
3. Edit the project's workflow:
* Go to **Administration** > **Projects**
* Click the pencil icon on the workflow
4. Existing transitions example:
5. Add restricted transition (e.g., TODO → Completed) for integration user:
* Click **Add Transition**
* Click **Conditions**
* Select **User Is In Group**
* Choose the `integration-users` group
6. Transition is now restricted to the integration user only.
7. Repeat for all required transitions.
8. Click **Publish Draft** to save.
> **Note:** This approach is valid if you do not wish to configure advanced workflow mapping in space.vars.SITENAME.
### Overwriting Meta
Use this feature to:
* Override field data types (e.g., text, HTML, wiki)
* Mark links or fields as **mandatory**
* Skip linking **archived entities** if Jira blocks them
**Important:**
* Use only for multi-line text fields like *Description* or *Environment*.
* If using a plugin like [JEditor](https://marketplace.atlassian.com/apps/1210768/jeditor-rich-text-editor-for-jira), ensure data types match what Jira expects.
If you overwrite a field data type used in mappings, you must **remap** that field manually.
#### JSON Format Example:
```json
{
"common": {
"fields": {
"system": [
{
"displayName": "Description",
"dataType": "wiki"
},
{
"displayName": "Custom Text",
"dataType": "html",
"mandatory": true
}
]
},
"relationship": {
"linkTypes": [
{
"linkType": "Parent Link",
"mandatory": true,
"archivedItemLinkSettings": {
"skip": "true",
"skipForIssueTypes": ["Bug", "Epic"]
}
}
]
}
},
"specific": [
{
"entityType": "Bug",
"fields": {
"system": [
{
"displayName": "Custom Text",
"dataType": "html"
}
]
}
},
{
"project": "WP",
"fields": {
"system": [
{
"displayName": "RichTextArea",
"dataType": "html"
}
]
}
},
{
"entityType": "Story",
"project": "TES",
"fields": {
"system": [
{
"displayName": "Description",
"dataType": "html",
"mandatory": true
},
{
"displayName": "Comments",
"dataType": "text"
}
]
},
"relationship": {
"linkTypes": [
{
"linkType": "Epic Link",
"mandatory": true,
"archivedItemLinkSettings": {
"skip": "true",
"skipForIssueTypes": ["Epic"]
}
}
]
}
}
]
}
```
* There are a few things to be taken care of while inputting the JSON data:
* As shown in the example, the project should be provided in form of Project Key. The user can get the project Key of a Project in Jira by looking at any entity's ID created in a Project. Let's say there is an entity called WP-23, then the Project Key for that project will be WP.
* The Project keys, Entity type names and Field names are all case sensitive. Their case should be exactly seen as it is on the Jira UI.
* Field Metadata Configuration:
* Only three data types are supported to be overwritten as of now: html, wiki and text.
* The **fields** in json structure supports two field metadata nodes:
* **system**: This node contains metadata for system fields that are standard fields within Jira.
* **custom**: This node contains metadata for custom fields created specifically for a Jira instance.
* The **system** or **custom** JSON node can contain only the field's "displayName", "dataType", and "mandatory" information.
* Link Metadata Configuration:
* The **relationship** node is used to mark the specific link types as mandatory.
* Overwrite is allowed only for standard Jira link types, including Epic Link, Parent Link, Sprint Link and Jira issue linkage (e.g. cloned, is cloned by, blocks, is blocked by). > **Note** The JSON input does not support Jira plugin-based links for marking them as mandatory.
* If the **skipForIssueTypes** field is specified, issue linking will be skipped only for the mentioned archived issue types when the end system returns an error during linking; if it is not specified, the skipping behavior will apply to all issue types by default in such cases.
* At least one key, either entity type or project is mandatory in each **specific** JSON key node. Notice how in the above example, in all 3 **specific** child nodes, there is at least **entityType** key or Project Key **present**.
* If either of the nodes, **common** or **specific** is not required then one of them can be omitted.
* Metadata configuration provided in the **specific** node will overwrite the metadata specified in the **common** node. For example, if the Description field is using a Wiki renderer in all projects but is using a HTML renderer for a specific project, then the user can keep the data type for Description as wiki in the **common** node and as html in the **specific** node for the respective projects.
* Here are a few JSON inputs for some use cases as examples:
| **Scenario** | **Minified JSON to Input** |
| ------------------------------------------------------ | ------------------------------------------------------------------------------------------------------- |
| **Change data type for all projects and entity types** | \`{"common":{"fields":{"system": \[{"dataType":"html","displayName":"Description"}] }},"specific": \[]} |
```json
{
"common": {
"fields": {
"system": [
{
"dataType": "html",
"displayName": "Description"
}
]
}
},
"specific": []
}
```
| **Scenario** | **Minified JSON to Input** |
| ---------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| **Change data type for a specific entity type for all projects** | `{"common":{},"specific":[{"entityType":"Bug","fields":{"system":[{"dataType":"html","displayName":"Description"},{"dataType":"html","displayName":"Comments"}]}}]}` |
```json
{
"common": {},
"specific": [
{
"entityType": "Bug",
"fields": {
"system": [
{
"dataType": "html",
"displayName": "Description"
},
{
"dataType": "html",
"displayName": "Comments"
}
]
}
}
]
}
```
| **Scenario** | **Minified JSON to Input** |
| ------------------------------------------------------------------------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| **Change data type of field for a specific entity type of a specific project** | `{"common":{},"specific":[{"entityType":"Story","project":"AUT","fields":{"system":[{"dataType":"html","displayName":"Description"},{"dataType":"html","displayName":"Environment"}]}}]}` |
```json
{
"common": {},
"specific": [
{
"entityType": "Story",
"fields": {
"system": [
{
"dataType": "html",
"displayName": "Description"
},
{
"dataType": "html",
"displayName": "Environment"
}
]
},
"project": "AUT"
}
]
}
```
| **Scenario** | **Minified JSON to Input** |
| ---------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| **Mark link as mandatory for a specific entity type for all projects** | `{"common":{},"specific":[{"entityType":"Bug","fields":{"system":[{"dataType":"html","displayName":"Description"},{"dataType":"html","displayName":"Comments"}]},"relationship":{"linkTypes":[{"linkType":"Parent Link","mandatory":true}]}}]}` |
```json
{
"common": {},
"specific": [
{
"entityType": "Bug",
"fields": {
"system": [
{
"dataType": "html",
"displayName": "Description"
},
{
"dataType": "html",
"displayName": "Comments"
}
]
},
"relationship": {
"linkTypes": [
{
"linkType": "Parent Link",
"mandatory": true
}
]
}
}
]
}
```
### Xray Entity Names
* This field is used to determine the changed entity names for Xray Cloud. This field is not mandatory.
* The input includes entity's original display name (default name when plugin was installed) and the corresponding current display name.
* Change the **currentEntityDisplayName** field in case of entity rename.
> **Note** The values for defaultEntityName field are pre-defined. Do not change its value.
* Here is the structure of the JSON input:
```json
[
{
"defaultEntityName": "Test",
"currentEntityDisplayName": "Test"
},
{
"defaultEntityName": "Precondition",
"currentEntityDisplayName": "Precondition"
},
{
"defaultEntityName": "Test Set",
"currentEntityDisplayName": "Test Set"
},
{
"defaultEntityName": "Test Plan",
"currentEntityDisplayName": "Test Plan"
},
{
"defaultEntityName": "Test Execution",
"currentEntityDisplayName": "Test Execution"
},
{
"defaultEntityName": "Test Run",
"currentEntityDisplayName": "Test Run"
}
]
```
* When no JSON input is provided:
* The current entity display names will be determined based on the entity descriptions provided in Jira.
* The description must be in this format: **This is the Xray Issue Type**.
* Example: If the entity name is 'Precondition', the description must contain the text, **This is the Xray Precondition Issue Type**.
### R4J Folder numbering
* In R4J tree, numbering of folders is present in each folder name. The synchronization of this numbering is not supported due to API unavailability. For information on numbering please refer. In the following image, '1)' and '1.1)' numbers will not get synchronized.
### Find Zephyr Custom Field Id
* Log in into Jira with a user having the Jira administrator's global permissions.
* Click Settings -> Apps. Under **Zephyr Squad** section, click **Custom Fields**.
* Press F12 to open the developer tools window and switch to \* \*Network \* \* tab. Reload the web page. \* To find custom field id of Test Execution entity: \* There should be a request named \* \*customField?entity=EXECUTION \* \* under the \* \*Name \* \* section in the developer tools window. \* To find custom field id of Test Step (field of Test entity): \* Click on the \* \*Test Steps \* \* section. \* There should be a request named \* \*customField?entity=TESTSTEP \* \* under the \* \*Name \* \* section in the developer tools window. \* Select the request and switch to \* \*Response \* \* tab.
* This would be a JSON response of the custom field details. Here is an example:
```json
{
"2f73f23b-9da7-497e-b39a-f9cb11842af6": {
"id": "2f73f23b-9da7-497e-b39a-f9cb11842af6",
"name": "Zephyr_Text_Field",
"description": "This field is used in the project. Don't delete this field.",
"entity": "EXECUTION",
"customFieldType": "TEXT"
}
}
```
* From the above JSON response, get the **id** parameter of the required custom fields.
### Find Test Cycle Id
* Log in to Jira.
* Create a Test entity and add it to the Test Cycle whose internal id is required.
* On the **Cycle Summary** window, click the **Detail** view highlighted in the image below.
* Click the Test Cycle **name** highlighted in the image below:
* Test Cycle id should be available in the URL of the browser as the value of \* \*cycle.id \* \* parameter. Here is an example of the URL:
```
/projects/NNREC?version.id=10676&cycle.id=4235b429-3c90-4f3a-99d2-db0156faa501&selectedItem=com.thed.zephyr.je__cycle-summary
```
### Enable Cookie Based Authentication
* From Jira version 10.2.x onward, if cookie-based authentication is enabled, you need to add a new JVM argument and set its value to "true".
* For the detailed steps, refer here:
* For example, use the argument: `-Datlassian.authentication.legacy.mode=true`.
* **Reason**: Jira has introduced an additional authentication layer starting with version 10.2.x. For more details, refer to [upgrade notes](https://confluence.atlassian.com/jirasoftware/jira-software-10-2-x-upgrade-notes-1455425770.html).